現在流通在網路上的資料都有一個優點"容易複製及抄襲",輕而和解,重而侵權被告,所以在網路上要引用或參考他人資料都要確實地註明引用來源及參考資料網站。
但網路爬蟲機制只要在電源開啟狀態根據使用者的指令都會不眠不休地到別人的網站抓取內容,是否合法?
基本上來說,網路爬蟲和網頁擷取並不違法,像是Google搜尋引擎就是一個典型的例子,大家都能透過Google搜尋到想知道的資料,而這些資料也都是Google伺服器透過網路爬蟲機制來產生的。
但還是要取決於如何正確地使用網路爬蟲及如何正確地使用抓取到的資料,如果過度使用網路爬蟲也有可能造成別人伺服器很大的負擔。或者透過爬蟲機制來攻擊網站,那肯定就會違法了。
所以,在爬蟲世界有一些規定及規範。
遵守robots.txt的規範
要確保遵守robox.txt文件中定義的規範,此文件通常會在網站的根目錄中,使用方式直接在想要爬蟲的網址後面加上/robots.txt 就能看到了
這邊用Facebook (https://www.facebook.com/) 來當範例
這邊是Disallow 不允許爬蟲的部分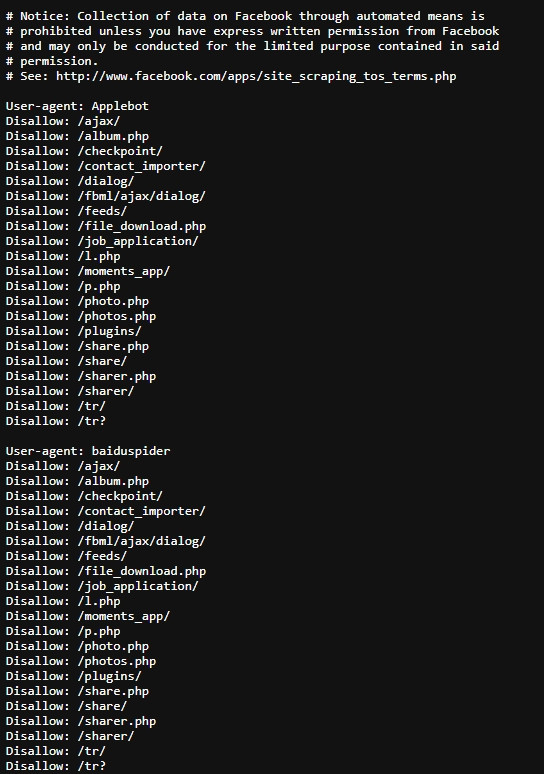
這邊是Allow 允許爬蟲的部分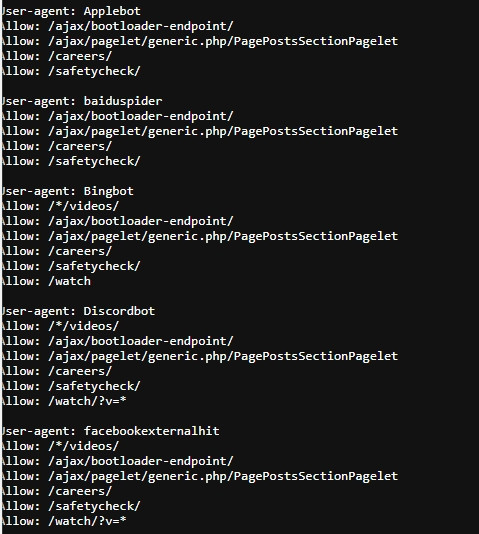
所以在爬的時候要先檢查一下想爬的資料能否爬,不然會得不償失啊~
不造成網站伺服器的負擔
如果網站伺服器負載過高到負載可以處理的上限時,就會無法reply any requests,所以使用網路爬蟲時建議需要在多次的請求之間加入適當的等待delay,才不會造成伺服器太大的影響及負擔。
確認網站是否有提供API
Application Programming Interface(API),是應用程式和應用程式之間溝通的工具。API就像一個介面,可以有效地幫助開發者節省精力,並且快速達成目的。
而目前許多網站都有提供API,讓第三方直接取得資料,所以在開發網路爬蟲之前,可以先確認網站是否有提供API,有的話就能直接使用API,就不用再去研究又臭又長的HTML結構了。
淺學爬蟲就先到這邊
接下來要開始談圖片辨識的基本概念及原理,最後會嘗試軟硬體結合描繪出人像。
參考資料:https://www.webscrapingpro.tw/what-is-web-scraping/


 iThome鐵人賽
iThome鐵人賽